A Survey of Code Foundation Models

记录一些在实践代码大语言模型过程中的经验和总结,本篇是关于代码大语言基座模型的相关内容,包括部分经典的代码大语言模型、以及对应的训练数据集和训练策略等信息的收集,其中StarCoder, Deepseeker Coder 以及 CodeLlama 占据相对较多的介绍篇幅。内容均来源于公开论文,不涉及商业敏感信息。
Code LLM 概述
代码大语言模型相比于通用大语言模型来说,有一些自己的特点[1],比如,
- 代码有自己严格的语法结构,可以提取语法结构信息
- 代码可以执行,得到执行验证反馈信息
考虑到代码任务的特殊性,从模型架构上看,一般来说,encoder-only结构擅长做代码的理解,而decoder-only结构擅长做代码的生成。 从模型大小上来说,我们一般把参数量1~10B级以上的语言模型都能称之为大语言模型(LLM),考虑到推理时延要求和性能的平衡,当前代码大语言模型的战场有收敛到10B级别的趋势。
从代码大模型的演进路径来看,很多paper已有过整理,这里借用A survey of neural code intelligence: Paradigms, advances and beyond的图进行汇总[2].
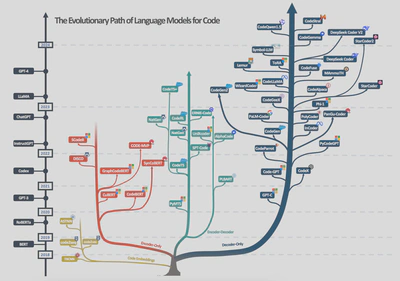
对代码大语言模型的技术实现有几个维度值得关注[1]:
- 利用代码结构,比如句法结构Abstract syntax tree (AST) 和 data-flow graph等
- 利用代码的execute trace,包括对编译反馈、执行结果等进行reflection
- 通过提升模型复杂推理的能力,包括COT、TOT、PoT等对thoughts的推理能力进行提升
- 协作型的 multi-agent,比如分角色、编码流程、通过角色间的沟通协作来实现复杂任务(这部分在未来code agent部分专门展开)
下面我们对一些代表性代码大语言模型的关键特点进行摘要。
CodeBERT
微软在2020年提出的CodeBERT,是第一个基于BERT的双语(natual language (NL) 和 programming language (PL))代码预训练语言模型。模型结构与RoBERTa-base一致,模型参数125M。通过微调可以用于下游的code search 和 code-to-text generation tasks。 其预训练目标包含: masked language modeling(MLM) 和 Replaced Token Detection (RTD) 两个任务,其中MLM任务是经典的BERT MLM任务,RTD任务是针对代码的token替换任务,通过替换代码中的token,来预测替换后的token。
训练数据来源于Github, 收集了 2.1M bimodal datapoints (NL-PL pair) and 6.4M unimodal codes (PL-only) across six programming languages (Python, Java, JavaScript, PHP, Ruby, and Go). 数据清洗规则包括:1) 该项目需要至少被一个其他项目引用; 2)文档截断到第一段; 3)删除短于3个token的代码; 4)删除函数短于3行的代码; 5)删除函数名包含test的代码。
GraphCodeBERT
GraphCodeBERT 在 CodeBERT 的基础上增加了对代码结构性信息的处理。在预训练中引入了代码的语义信息,即data-flow, 使用data-flow的graph可以很好的表示变量间的来源关系,即where the values comes from. 预训练的数据集使用 CodeSearchNet dataset, which includes 2.3M functions of six programming languages paired with natural language documents.
预训练目标有: masked language modeling(MLM), Edge Prediction 和 Node Alignment 三个任务,其中MLM任务是经典的BERT MLM任务,Edge Prediction任务是预测data-flow graph中两个节点之间的边,Node Alignment任务是预测data-flow graph中的 node 和source code 中的token是否是同一个变量。
CodeT5
CodeT5 是基于 T5(Text-To-Text Transfer Transformer)架构,将所有编程语言相关的任务转换为文本到文本的统一任务形式。 设计了一种 identifier-aware pre-training task,使模型能够区分哪些是code token,并在其被masked的时候,进行恢复。 CodeT5中有四个预训练任务:
- Masked Span Prediction,随机遮蔽的是代码片段而不是单个 token,要求模型预测被遮蔽的代码片段;
- Identifier Tagging, 判别是否为code token 标识符。它本质上是一个序列标注任务,能够捕捉到代码的语法以及代码中的数据流结构;
- Masked Identifier Prediction (MIP), 对代码中的所有标识符进行mask,并对同一标识符的所有出现,采用唯一的标记,要求模型预测被遮蔽的标识符。这里模仿了:更改同一个标识符的名称并不会影响代码语义的代码特性;
- Bimodal Dual Generation, 文本片段生成代码片段任务,或反之。来弥补下游任务和预训练任务之间的差距。
预训练数据跟GraphCodeBert 类似,使用了CodesearchNet dataset, 并加入了BigQuery数据集中的c/cshape子集, 总共 8.35 M. 作者使用 BPE 训练了一个 Code-specific Tokenizer,在下游任务上,能降低30%~45%的token 数。
另外,CodeT5+在此基础之上,加入了因果、对比、匹配等更多的预训练任务。在此不再展开。
UniXcoder
论文中给出了一个结论:Comments和AST都能够增强大模型的代码表征能力。尽管UniXcoder是一个encoder-decoder架构,但是作者在预训练任务中使用了三者注意力方式:
- Masked Language Modeling使用标准的encode-only
- Unidirectional Language Modeling 使用decoder-only的自回归方式,来模拟代码补全任务
- Denoising Objective DeNoiSing (DNS),随机mask一个片段,使用了标准的encode-decode方式,强化代码总结等生成式任务
- Code Fragment Representation Learning,使用多模数据来学习代码的语义表征,其中包含multi-modal contrastive learning 和 cross-modal generation两个任务。这里还使用到了AST的序列信息和Comments.
UniXcoder的预训练数据来自于 C4 和 CodeSearchNet,然后在下游任务是使用对应任务的training set,暂不展开。
Codex
Codex 是在GPT3之后,OpenAI 专门针对代码数据进行增强训练后得到的代码大模型, 它是GitHub Copilot背后的基座模型。这篇论文验证了使用Python docstring 生产python 函数的能力,并提出了HumanEval benchmark 数据集。
预训练数据:基于GitHub上面的54M个公开repo,收集1Mb以下的python文件(共179GB);过滤规则:100<平均长度<1000, 字母数字符号比率约束; 最总共保留159GB 的python文件。
论文有一个有意思的发现:从头使用代码数据训练和基于GPT-3进行finetuning的结果是一样的,尽管finetuning 收敛的更快。这里反过来说:大模型在Python代码生成任务上,不需要额外的数据增强,只需要使用 Python 代码数据即可?。不过,从后面大语言模型的训练来看,学习语言对编程应该是有用的。
总之,Codex 使用沙箱执行验证,通过自建单元测试集,基于单元测试的执行结果,来验证代码生成的正确性。在代码大模型历史上是重要的一笔。
StarCoder
StarCoder 是 BigCode 开源研究项目发布的系列代码大语言模型,该项目由 Hugging Face 和 ServiceNow 共同发起,旨在推进Code LLMs技术的发展。
StarCoder 有两个版本,主要是从源码,以及源码相关的活动数据(如Github issue,git commits等)进行训练,其中 StacCoder v1 对应的训练数据集是 Stack v1.2;stackCoder v2 对应的是 Stack v2 数据集。数据对大模型的训练至关重要,论文中包含了比较详细的数据处理过程,下面我们分别讨论。
| Source | Stack v1 | Stack v2 |
|---|---|---|
| full | 6.4TB | 67.5TB |
| dedup | 2.9TB | 32.1TB |
| train (full) | ~200B tokens | ~900B tokens |
| #programming language | 358(384)->86 | 619->? |
StarCoder1 (@Stack v1.2)
编程语言的过滤
- 覆盖86种编程语言,选择上考虑了类别数据量的大小(大于500MB)以及 语言流行度(TOBIE programming language popularity 榜单top50)
- 以文件后缀进行类别划分,进行人工检视。判断是否是代码片段,并对是否需要使用 alpha-numeric filter 和 long-line filter 进行检查。最终过 excluded 36 extensions and eliminated the long-line filter for 27 extensions.
- XML filter, 检查前100 个字符中是否含有 <?xml version=, 过滤掉XML文件
- Alpha filter, 部分后缀文件包含大量的数据内容,如matlab。过滤掉字母比率低于25%的。该约束会误伤一些语言(如Assembly),仅人工check,最终只对25种后缀文件进行该过滤
- HTML, 保留可见文本大于20%,总长度大于100字符的文件
- JSON and YAML, 过滤量较大
- Yaml: 50 < yaml 字符数 < 5000 & average length < 100 & max length < 1000 & alphabetic characters ratio > 50%
- Json: 50 < json 字符数 < 5000 & alphabetic characters ratio > 50%
Jupyter notebooks
对于jupyter notebook有两个操作,
- We utilize Jupytext to convert notebooks to scripts;
- 提前含python代码的notebook 构造code-text pair (Jupyter – structured)
GitHub issue
- 移除issue中自动生成的文本(如emial信息),删除过短信息(200字符),截断过长信息(前100行&最后20行)
- 去除bots生成的comments
- 通过参与人数来定义issue的质量,保留参与人数>=2; 删除那些某一个人参与issue多(>10 events)同时低参与度的issue
- 使用 fasttext 库移除non-englist的issue,这个跟后面个人信息检查相关
Git commits
针对 Git commit的过滤规则较多,包括:最大字符数,最少的改变行数以及比例,修改字符长度以及比例,过滤空commit 以及自动commit,空格分隔后的单词数占字符的比率,以及下采样 四种结构化(JSON, YAML, XML, HTM)数据的commits。总的来说这些规则过滤掉了大量的commit,从4TB的commits中仅保留64GB,约1%了。这些规则在具体的数据处理过程中可以根据量的约束,进行合理的参数调整。
Deduplication 去重
使用MinHashes 对所有源码去重,实现上使用Locally Sensitive Hashing (LSH)分桶相似代码,参数使用 5-grams and a Jaccard similarity of 0.7.
Weighting of data sources 配比
- 经过前面的去重过程,对于top语言类型基本上呈相似数量,即44~87GB (如C, C++, C#, Java, Javascript, Python, and PHP), 因此对于这些数据保留了原来的配比量
- 而对于那些结构化的数据,如JSON,YAML,CSS进行了下采样,分别保留1 GB for JSON and YAML, and 3GB for CSS.
Personally Identifiable Information (PII) 移除
使用众包的方式,标注了一批PII数据集,然后训练PII检测模型,并将识别到的PII信息进行特殊token的替换,特征字符包括:
<NAME>, <EMAIL>, <KEY>, <PASSWORD>
论数据清洗的重要性,很多时候还是需要人工double check的过程中,持续迭代过滤规则 :(
模型训练
- 代码数据组装格式上,保留了库名、文件名、star数三个meta信息,以及其他格式组装的格式为
# code
<reponame>reponame<filename>filename<gh_stars>stars\ncode<|endoftext|>
# issue
<issue_start>Title: title\nusername_id0:comment0<issue_comment>username_id1:comment1
... <issue_closed (optional)><|endoftext|>
# jupyter
<jupyter_start><jupyter_text>text0<jupyter_code>code0
<jupyter_output>output0<jupyter_text> ... <|endoftext|>
# git commits
<commit_before>code_before<commit_msg>message<commit_after>code_after<|endoftext|>
- 词表,基于BPE训练的49152 大小的词表
- 模型参数量 15.5B, 绝对位置编码,使用了fill-in-the-middle (FIM) 任务策略, 8K context length.
- Adam 优化器,warmup 2000 iterations. 使用了 Megatron-LM’s distributed optimizer.
- StarCoderBase is the first model trained on 1 trillion tokens.
- StarCoder is the fine-tuned version of StarCoderBase, trained on another 35B Python tokens (roughly 2 epochs).
另外,论文中有提到,专门针对benchmark数据集进行消毒,包括Humaneval, APPs, GSM8K and DS1000.
StarCoder2 (@Stack v2)
Stack v2 数据集
Stack v2 是 StarCoder2 使用的训练数据集,相比 Stack v1,有以下主要特点:
- 数据量扩展:训练数据量增加了约四倍,超过 600 种编程语言,同时时间覆盖更广,大幅增加了语言多样性。
- 数据类型扩充:除了代码,还包括:pull requests, Kaggle, 代码文档, 以及与数学、编程和推理相关的自然语言数据集(包括Intermediate Representations, 一些榜单的training set,如APPs, GSM8K,以及Stack Overflow,ArXiv,WikiPedia数据等)
- 数据清洗流程,提升数据质量,仅列出部分差异:
- 数据类别从文件后缀升级到了go-enry算法
- 增加了对encode data的过滤,使用正则对base64,Hexadecimal,Unicode文本比例超过50%,或者大于1024长度的过滤
- 增强了隐私保护措施,特别是对数据licence相关的分析处理
StarCoder2 模型
StarCoder2 相比前代v1模型有以下改进:
模型规模:提供了 3B、7B 和 15B 三种参数规模的模型,训练数据量分别是3.1T, 3.5T, 4.1T, 均训练 5 epoches 左右
训练优化:
- 位置编码升级到了 Rotary Positional Encodings (RoPE)
- 注意力机制从 Multi-Query Attention (MQA) 升级到 Grouped Query Attention (GQA)
- 使用了更大的批次大小, 4k(pretraining)->16K(finetune)
- 尝试过训练 100k 大小的tokenizer,但是没有性能提升,还是保持49152大小,但是从GPT-2 pre-tokenizer来,并加入了sentinel tokens
CodeAlpaca
CodeAlpaca 是一个基于指令微调的代码生成模型,由斯坦福大学的研究人员开发。它是在 LLaMA 7B 模型的基础上进行了进一步的微调,专门用于代码生成任务。
- code_alpaca_20k instruct 训练集,涵盖了各种编程任务,如代码生成、调试、重构等。基于 text-davinci-003,使用self-instruct 方法得到 code_alpaca_20k.json
Self-Instruct 是一种指令数据构造方法,主要包含四个主要步骤:0) 人工编写种子指令; 1) 利用大模型生成新指令; 2) 分类任务识别,分别考虑input/output-first; 3) 使用模型为指令生成实例;4) 过滤,整理生成的指令-答案对构建数据集,然后循环1~4步骤。
WizardCoder
WizardCoder 是由 WizardLM 团队开发的专门用于代码生成的大型语言模型。它基于 StarCoder 模型进行指令微调(后面也做了其他基座模型),旨在提高代码生成和理解能力。下面重点介绍Evol-Instruct合成数据的方法。
Evol-Instruct 是一种进化式的指令生成技术,从深度、广度等维度进行进化,然后再根据评价标准进行淘汰(Elimination)演进。 旨在创建复杂、多样化的指令数据。这里针对code领域场景,进行优化适配,优化的数据源是Code Alpaca,其主要步骤包括:
- 初始化:从Code Alpaca种子指令数据集开始。
- 变异:使用大语言模型对现有指令进行In-Depth and In-Breadth Evolving变异,
- In-Depth, 如增加时间-空间复杂度、改变任务类型(如code debugging)、添加约束条件等。
- In-Breadth, 如增加topic, skill等来覆盖长尾数据,进而增强数据的多样性;WizardCoder这里暂未使用,实际上code场景是可以有很多breadth的扩展方式。
- 根据上一步得到的指令,获取response。
- 选择/淘汰(Elimination):使用预定义的标准(如信息增量,时间/空间复杂度、是否含特殊词元)评估变异后的指令数据,保留高质量的变异指令,淘汰低质量的指令。
- 迭代:重复步骤 2-4,不断优化指令集。
这种方法能够生成更高多样化、具有复杂挑战性的指令,有助于提高模型的泛化能力和对复杂任务的处理能力。
Magicoder
Magicoder 提出了一种叫 OSS-INSTRUCT的数据合成方法,用以减少 LLM 的固有偏见,释放LLM创造高质量和创造性代码指令的潜力。
OSS-INSTRUCT 是一种简单有效的数据合成方法,它首先从开源环境(如 GitHub 和 Stack)中收集种子代码片段。随后,利用大型语言模型(LLM)围绕这些种子片段生成编码问题和相应的解决方案。这种方法不仅确保了生成内容的可控性,还促使 LLM 创造出多样化且贴近实际的编程场景。这些场景涵盖了广泛的编程任务,从简单的算法挑战到复杂的应用程序开发,包括但不限于单函数代码生成、基于特定库的程序补全,以及完整的软件系统构建等。
到这里为止,我们连续讲了三种合成代码数据的方法,self-instruct->evol-instruct->oss-instruct. 他们是依次递进的数据合成方案。这里我们略微总结一下代码数据。
- 从数据使用形态来看,代码结构化信息的显式使用越来越少。各家模型倾向于直接构造复杂、多样、高质量的代码数据。
- 代码训练数据量也基本上到了T级别,训练支持多种语言类型
- 代码的评测数据从文本匹配,基本上过渡到单元测试用例的执行反馈为主
CodeGeex
CodeGeeX 是清华大学和智谱AI联合发布的一个13B参数代码大语言模型,它在23种编程语言上进行训练,语料来自Pile、CodeParrot数据集。CodeGeeX一个重要的贡献是扩展了Humaneval 测试集,发布包含:Python, C++, Java, JavaScript, and Go 五种语言的测试集HumanEval-X。 另外还支持VS code 插件。
Deepseek Coder
DeepSeek Coder 是由 DeepSeek 公司开发的代码大语言模型,目前已开源发布了 v1 和 v2 两个版本,也是目前坚守MOE架构的代表。
DeepSeek Coder v1
DeepSeek Coder v1 于2024年1月发布,是一个专门针对代码生成和理解任务的大型语言模型。其主要特点包括:
架构提供了 1.3B、6.7B 和 33B 三种参数规模的模型,均使用SwiGLU 激活函数;前两个小规模的使用Multi-head注意力机制,而33B规格的使用了GQA。
使用了 2T tokens 的高质量代码数据(87% code and 13% natural language in both English and Chinese)进行训练,涵盖了87种编程语言。特别强调了高质量的project-level 的代码语料。数据清洗规则基本上跟StarCoder 类似,主要是差异在于 对repo-level数据的处理,包括去重,依赖关系、文件顺序排列、调用关系以及路径信息相关处理。
- GitHub’s Markdown and StackExchange1, which are used to enhance the model’s understanding of code-related concepts and improve its ability to handle tasks like library usage and bug fixing
- the Chinese corpus consists of high-quality articles aimed at improving the model’s proficiency in understanding the Chinese language.
支持 16K tokens 的上下文长度。
训练策略:
graph LR A["代码预训练"] --> B["长上下文预训练"] --> C["指令微调"] A["代码预训练 1.8T tokens, 4K窗口"] B["长上下文预训练 200B tokens, 16K窗口"] C["指令微调 2B tokens指令数据, 16K窗口"]- Step 1. Pretraining from scratch, 使用包含87%代码、10%代码相关语言(GitHub Markdown和StackExchange)和3%非代码相关中文的数据集。共 1.8T tokens,以4K窗口大小进行预训练。预训练任务包含 Next Token Prediction 和 Fill-in-the-Middle.
- Step 2. 使用16K扩展窗口大小对额外200B tokens进行进一步预训练,得到基础模型(DeepSeek-Coder-Base)。
- Step 3. 对2B tokens的指令数据进行微调(16k window),得到指令调优模型(DeepSeek-Coder-Instruct)。
实验部分达到SOTA按住不表,但有一个有趣的发现:在"Continue Pre-Training From General LLM"的实验中,使用通用语言模型继续训练代码数据时,模型的代码能力略有下降,但数学以及其他通用能力有显著的提升。这个结果表明,在专业领域(如代码)和通用能力之间可能存在一定的权衡关系,值得进一步研究和探讨。另外需注意的是:v2版本是从Deepseek-v2 的中间 checkpoint 继续预训练6TB tokens 而来。
DeepSeek Coder v2
DeepSeek Coder v2 于2024年6月发布,它使用了MoE(Mixture-of-Experts)架构。
- 模型规模:提供了 16B 和 236B 两种参数规模的MoE模型,激活参数量分别是2.4B和21B。LR scheduler 均使用 Cosine.
- 训练数据:共使用了 10.2T tokens 的训练数据,包括代码、通用文本和数学数据。支持 128K tokens 的上下文长度(with Yarn),支持338种编程语言。
- Pre-training phase, 60% source code (from github, CC), 10% math corpus(from CC), and 30% natural language corpus(来自deepseek 通用语料), 覆盖338种编程语言。总的来说,共10.2T token,其中4.2T来着通用数据(严格说应该是deepseek v2 先训练4.2T的通用语料),6T 来自coder 数据集
- Alignment (instruction, SFT) phase, 20K code + 30K math + 通用, total 300M tokens
- Reinforcement learning phase, Preference data is collected in the coding domain using compiler feedback and test cases. 总共约 40K 的数据量
- 清洗规则,与deepseeker coder v1 保持一致,即跟之前 StarCoder 的处理方式类似。
- GitHub 数据收集的覆盖时间,从v1 的 2023.2月 拉长到了 2023.11月
- 从 CC 种捞代码和数学相关数据时,考虑了 StackOverflow, library sites such as PyTorch documentation, and mathematics website such as StackExchange 这些专业性站点。并训练了fastText 模型进行数据召回(同样跟starcoder一致)
- new code corpus consists of 1,170B code-related tokens sourced from GitHub and CommonCrawl.
- 训练策略:
- 小号16B的使用了两种预训练任务:Next-Token-Prediction and Fill-In- Middle (FIM) ,而大号的236B 只使用了 Next-Token-Prediction 任务。
- Long Context Extension:
- In the first stage, 32K and a batch size of 1152 for 1000 steps.
- In the second stage, additional 1000 steps, 128K and a batch size of 288 sequences.
- Supervised Fine-Tuning
- cosine schedule with 100 warm-up steps and an initial learning rate 5𝑒−6
- Reinforcement Learning
- 通过 compiler signal 训练reward model
- 使用 Group Relative Policy Optimization (GRPO) 算法
注意:刚刚最新发布的deepseek v2.5 (2024.9.5) 已经将coder v2 和 chat 模型进行了合并统一
CodeLlama
CodeLlama 是由 Meta AI 研究团队开发的一系列大型语言模型,专门用于代码相关任务。它是基于 Llama 2 模型进行进一步训练而来的。不同规格的 CodeLlama 模型的训练 Pipeline 如下图所示。
图中,Infilling-capable models are marked with the $\scriptsize \rightleftarrows$ symbol. 这里有几个信息值得关注:
- 基座 Llama 2 训练 2T tokens of text (其中含 80B tokens of code).
- 论文做了基于通用模型继续预训练和使用code 数据 train from scratch的对比实验,发现基于通用基座LlaMA 2 进行继续训练 loss下降得更快,差不多前者240B的数据量 跟后者的500B loss 差不多。(这里可以联想一下deepseek coder 也做了类似的实验)
- 第一阶段的代码数据训练,7B、13B、34B 基于Llama 2训练的500B tokens,但是70B的版本同一批代码数据训练两次,即训练了 1T tokens. (含 8% 代码相关的文本数据,以及少量通用文本数据)
- 使用BPE tokenizer, vocabulary size 32k (跟Llama1/2 一致).
- Infilling 训练任务,提升文本填充能力(如IDE中,随鼠标位置生成代码),这里增加了4个特殊token. 另外值得注意的是,开始版本的7/13B使用了infilling训练任务,但是34B的版本没有训练infilling任务;但是后面放出来的70B版本又加入了infilling 任务训练。
- Long context fine-tuning. 修改 RoPE 超参数,序列长度从 4k 扩展到 16k.
- Instruction fine-tuning.
- 该阶段首先使用了human feedback, human feedback 标注数据,以及 Self-instruct 合成数据(∼14,000 question-tests-solution triplets, interview-style)训练
- Rehearsal (感觉跟退火类似)。 为防止能力退化,抽取 6% code + 2% 的通用文本 数据进行训练。
Llama 3 针对code 有设计专门的 pipeline 提取网页中的code 和 math 数据(引用了deepseek)。并公开了不同训练阶段的策略。
Pre-Training
- 自定义 parser 来提取 原始的 HTML 内容(这个是很重要,小插曲。记得 beautifulSoup 提取 stack overflow 中的文本是会出现缺失的)
- 在每个编程语言类内,进行line-level (ccNet) and document-level (minhash) 的去重,
- 针对全量数据url-level 去重,使用模型、启发式规则 (n-gram, “dirty word” counting, token-distribution Kullback-Leibler divergence) 进行低质量代码过滤
- 基于Llama 2 标注数据,然后训练 DistilRoberta 进行数据质量过滤
- 设计 fasttext-based model 进行编程语言类型分类为 176 类
- final data mix contains roughly 50% of tokens corresponding to general knowledge, 25% of mathematical and reasoning tokens, 17% code tokens, and 8% multilingual tokens.
- annealing on small amounts of high-quality code and mathematical data can boost the performance of pre-trained models on key benchmarks.
- vocabulary size 128K, RoPE, GQA.
- 预训练过程中,batch size 逐渐增大。窗口也是从 8K 逐渐增到 128k. 另外数据配比也会动态调整。
Post-Training
post-training 包含多个阶段,并进行多轮迭代。依次进行 reward modeling, SFT, DPO, model average, 然后迭代六轮
其中有一些值得注意的点:
- SFT 使用标准的 cross entropy loss
- DPO 的优化目标加入了 NLL loss 的正则项
- preference data 中 code的占比 6.93%; 在 SFT 中,code 占比 14.89%
- 对拒答数据进行了细致的平衡
- 类别去重(采样),质量打分,难度打分,语义去重
- SFT 种使用了合成数据 2.7M, 合成数据有较详细的分析
- 合成数据考虑了长尾类别,代码质量检查上使用了静态分析、unit test 和 执行反馈等技术
- COT, throught 等信息的加入,是能帮助合成代码生成
- 通过代码翻译,帮助合成低频类别的编程语言
- 针对代码文档、解释等不能通过执行检验的语料合成,使用了一种 backtranslation 技术:首先,通过使用预训练语料种的code snippets生成注释、文档或者解释等;然后通过对生成的内容 转译 到原来的代码片段;最后使用模型对生成内容和原来代码片段进行校验过滤。
- 另外,针对一些伪代码,或者编辑型的代码,也会使用 model as judge.
CodeQwen
CodeQwen1.5 基于 Qwen 语言模型初始化,Qwen拥有 0.5B, 1.8B, 4B, 7B, 14B, 以及 72B 等多种参数尺寸的模型,CodeQwen主要是7B和14B两种尺寸;最大使用 ~3T tokens 代码相关的数据,使用 8K context length进行预训练。
- Qwen 架构上与Llama 类似:RoPE 位置编码,同时使用 Pre-Norm & RMSNorm,使用 SwiGLU 激活函数。
- 同样使用BPE tokenizer, 但是他的vocabulary size 152K,比LlaMA的词表 size 32K,大了不少.
- 不同于 codeLlama 仅使用代码和文本混合数据进行预训练,codeQwen在后面继续进行了code-only的pretraining.
- 工具使用了ReAct prompting技术,使用了 code interpreter.
Qwen 2 包含 dense 和 MoE 版本, 使用了 7T tokens 进行预训练。增加了更多高质量的代码数据,具体细节论文中披露不多。
Yi-Coder
Yi-Coder 是零一万物最近开源的代码大模型,包含 1.5B 和 9B 两种版本,每种规模都有基础模型和对话模型。Yi-Coder-9B 在 Yi-9B 的基础上,使用额外的 2.4T 高质量代码数据进行了继续预训练。其主要特点包括:
- Yi-Coder-9B 在 Yi-9B 的基础上,使用 2.4T 高质量代码数据训练,数据来自 GitHub 和 CC, 覆盖 52 种主要编程语言。
- 最大支持 128K 的上下文窗口,能够理解和生成repo-level代码。
- Yi-Coder-9B 性能达到 10B 级别 SOTA,接近 Deepseek Coder 38B 的性能。
Codestral
Codestral 是 Mistral AI 开源的一个 22B 参数量的代码大语言模型。支持 32k 的context length. 覆盖80+ 编程语言。
CodeGemma & Gemma2
CodeGemma 是 Google 基于 Gemma 基座进行继续训练的代码语言模型,有 2B 和 7B 两种规模。
CodeGemma 预训练数据量 1T tokens. 2B 尺寸使用 100% code,而 7B 尺寸使用 80% code-20% 自然语言混合数据。
Gemma2 是Google 最新开源的 Practical Size 大模型,Gemma Team 使用了一些技术来推动10B级别的大模型能在实际场景中可用。
- knowledge distillation with a teacher model
- modifications of Transformers, namely the interleaving of global and local attention layers; used GQA.
- Logit soft-capping
- Post-norm and pre-norm with RMSNorm
- Vocabulary size 256k
- 27B on 13 trillion tokens of primarily-English data, the 9B model on 8 trillion tokens, and the 2B on 2 trillion tokens.
- 与 Llama3 的 model averaging 类似,使用了model merging
GPT4o & Claude
在各大榜单上,比如LiveCodeBench, Arena’s coding category等,GPT4o 和 Claude 相比其他模型,code 能力基本上是大幅领先。他们俩都是闭源模型,没有太多训练数据和训练策略信息可查。 另外,从 GPT2 和 GPT3 的论文中可以看到, 在不同的训练阶段,code 数据都充当了重要的角色,包括前文提到的codex,也是在GPT3 的基础上训练的专用code模型。关于chatGPT的一些技术暂不在这里展开,争取专开一栏。
题外话:随着大模型技术的快速演进,不断有很多新的模型被提出,这里不再一一列举,感兴趣的可以参考[1]和[2],或自行Google。
Reference
- Yang, K., Liu, J., Wu, J., Yang, C., Fung, Y. R., Li, S., … & Zhai, C. (2024). If llm is the wizard, then code is the wand: A survey on how code empowers large language models to serve as intelligent agents. arXiv preprint arXiv:2401.00812.
- Sun, Q., Chen, Z., Xu, F., Cheng, K., Ma, C., Yin, Z., … & Wu, Z. (2024). A survey of neural code intelligence: Paradigms, advances and beyond. arXiv preprint arXiv:2403.14734.
- CodeBert, https://github.com/microsoft/CodeBERT
- GraphCodeBert, https://arxiv.org/pdf/2009.08366
- CodeT5, https://github.com/salesforce/CodeT5
- UniXcoder, https://arxiv.org/abs/2203.03850
- Codex, https://arxiv.org/pdf/2107.03374
- StarCoder: may the source be with you! https://arxiv.org/pdf/2305.06161
- StarCoder 2 and The Stack v2: The Next Generation https://arxiv.org/pdf/2402.19173
- Stack dataset in huggingface, https://huggingface.co/datasets/bigcode/the-stack-v2
- bigcode-project, https://www.bigcode-project.org/docs/about/the-stack/
- Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M. A., Lacroix, T., … & Lample, G. (2023). Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
- Wang, Y., Kordi, Y., Mishra, S., Liu, A., Smith, N. A., Khashabi, D., & Hajishirzi, H. (2022). Self-instruct: Aligning language models with self-generated instructions. arXiv preprint arXiv:2212.10560.
- Code Alpaca: An Instruction-following LLaMA model for code generation, https://github.com/sahil280114/codealpaca
- Stanford Alpaca: An Instruction-following LLaMA model, https://github.com/tatsu-lab/stanford_alpaca
- Xu, Can, et al. “Wizardlm: Empowering large language models to follow complex instructions.” arXiv preprint arXiv:2304.12244 (2023).
- Luo, Ziyang, et al. “Wizardcoder: Empowering code large language models with evol-instruct.” arXiv preprint arXiv:2306.08568 (2023).
- Wei, Yuxiang, et al. “Magicoder: Empowering code generation with oss-instruct.” Forty-first International Conference on Machine Learning. 2024. https://arxiv.org/abs/2312.02120
- Zheng, Qinkai, et al. “Codegeex: A pre-trained model for code generation with multilingual evaluations on humaneval-x.” arXiv preprint arXiv:2303.17568 (2023).
- Guo, Daya, et al. “DeepSeek-Coder: When the Large Language Model Meets Programming–The Rise of Code Intelligence.” arXiv preprint arXiv:2401.14196 (2024)., v1 github
- Zhu, Qihao, et al. “DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence.” arXiv preprint arXiv:2406.11931 (2024)., v2 github
- CodeLlama blog, https://ai.meta.com/blog/code-llama-large-language-model-coding/
- Roziere, Baptiste, et al. “Code llama: Open foundation models for code.” arXiv preprint arXiv:2308.12950 (2023).
- Touvron, Hugo, et al. “Llama: Open and efficient foundation language models.” arXiv preprint arXiv:2302.13971 (2023).
- Touvron, Hugo, et al. “Llama 2: Open foundation and fine-tuned chat models.” arXiv preprint arXiv:2307.09288 (2023).
- Dubey, Abhimanyu, et al. “The llama 3 herd of models.” arXiv preprint arXiv:2407.21783 (2024).
- Bai, Jinze, et al. “Qwen technical report.” arXiv preprint arXiv:2309.16609 (2023).
- Yang, An, et al. “Qwen2 technical report.” arXiv preprint arXiv:2407.10671 (2024). https://qwen.readthedocs.io/en/latest/
- Code with CodeQwen1.5. https://qwenlm.github.io/zh/blog/codeqwen1.5/
- Meet Yi-coder blog. https://01-ai.github.io/blog.html?post=en/2024-09-05-A-Small-but-Mighty-LLM-for-Code.md
- Codestral blog. https://mistral.ai/news/codestral/
- Gemma2 blog. https://blog.google/technology/developers/google-gemma-2/
- Team, CodeGemma. “Codegemma: Open code models based on gemma.” arXiv preprint arXiv:2406.11409 (2024).
- Team, Gemma, et al. “Gemma 2: Improving open language models at a practical size.” arXiv preprint arXiv:2408.00118 (2024).
- Radford, Alec, et al. “Language models are unsupervised multitask learners.” OpenAI blog 1.8 (2019): 9.
- Brown, Tom B. “Language models are few-shot learners.” arXiv preprint arXiv:2005.14165 (2020).
- Achiam, Josh, et al. “Gpt-4 technical report.” arXiv preprint arXiv:2303.08774 (2023).
- Blog, How does GPT Obtain its Ability? Tracing Emergent Abilities of Language Models to their Sources. website