
Agent 多轮长轨迹(Long Trajectory)技术概要
Agent 在多轮长轨迹任务中面临误差累积、上下文膨胀与奖励稀疏三大核心挑战。业界正通过数据合成与轨迹瘦身、后训练强化学习优化、前瞻性安全审计及细粒度多维评估四大技术路径破局,推动大模型从文本生成器向高阶序列决策系统蜕变。本文聚焦代码智能体等典型长轨迹、多轮交互场景,系统梳理前沿学术进展与工程实践。
Apr 11, 2026

A Few MORE Things About Code Agents: Decoding the Central Brain
前文《A few things about Code Agent》针对CodeAgent进行了全貌概述,这篇我们将针对其关键组件「中控大脑」进行展开——它怎么从早年堆 Prompt工程,一路摸到树搜索、PRM、RLVR,再到现在这种有点像 7×24 常驻「个人 AI OS」的玩法。不是教科书式的全景综述,更像我读论文、跟开源项目时随手捋的一条时间线,留给自己也留给同好。
Jan 2, 2026
深度强化学习方法-PG系列
基于policy gradient的强化学习方法的梳理总结,从经典的策略梯度算法开始,讨论A3C,DDPG,PPO,以及IMPALA等系列算法的基本思想和实现。
Jun 13, 2019
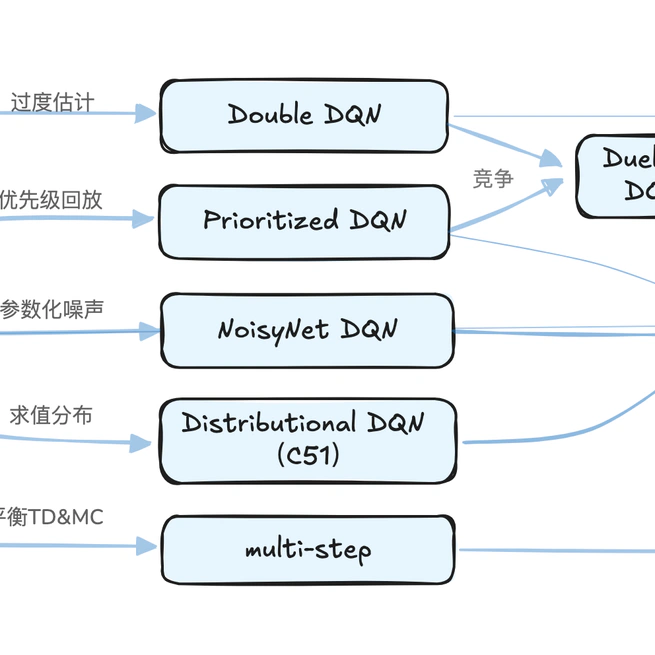
深度强化学习方法-DQN系列
基于dqn 的强化学习方法的梳理总结,从经典的DQN算法开始,总结不同方法的改进策略,到集大成者Rainbow算法。
May 13, 2019

强化学习系统库及仿真环境
梳理当前经典的强化学习开源库, 以及一些经典的仿真环境。
Apr 23, 2019
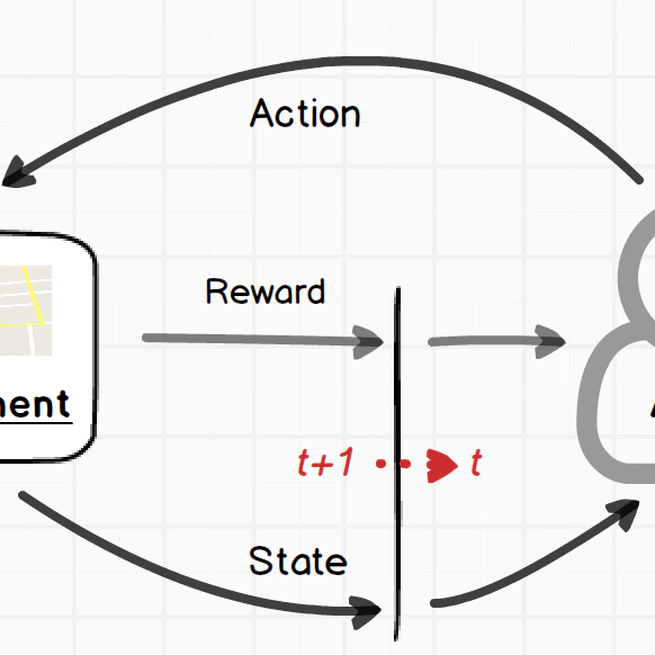
强化学习基本问题回顾总结
强化学习问题的概述,从问题定义,到分类,以及传统强化学习算法(主要覆盖DQN之前的RL经典算法,包括:动态规划、蒙特卡洛、时序差分q-learning和sarsa 等)。
Apr 13, 2019

PyBrain库的example之NFQ流程图分析
有关PyBrain 库中NFQ算法的流程图分析,包括数据处理和策略的优化pipeline.
May 27, 2016